
本来是为了方便视频剪辑,这项技术却足以成为真相的噩梦。
文 | 光谱
最近几年,出现了不少利用深度学习编辑视频的技术。
最著名的必然是 Deepfake,导致明星换脸视频肆虐色情网站;以及诞生于去年的 Deep Video Potrait (DVP),轻松生成以假乱真的演讲视频,让新闻机构和政治人物一度恐慌。
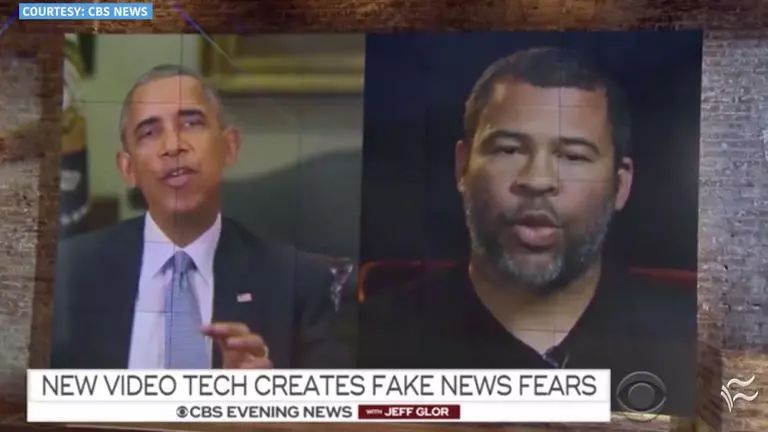
如果你以为这些就足够令人担忧,那你就太小看深度学习研究者了。在他们的眼中,只要是以科学的名义,没有任何技术是受限的——即便可能造成严重的道德危机。
最近,研究者开发出了一种通过深度学习去操纵视频的全新技术,可以在一句话中增加、删掉甚至是修改任意词句,让视频中的演讲者说出任意想说的话,而且看起来仍然十分自然,就好像演讲者自己说出来的那样。
比方说,财经电视台的原报道是“苹果股价收盘于191.45美元”,研究者将数字更改为“182.25美元”,在英文中发音和口型完全不一样的两组数字,最终效果很难看出来是被修改过的:

可怕之处在于:操纵视频的方法十分简单,只需要修改视频转录的文本即可。这个技术可以自己找到文本在视频中对应的位置,自动生成语音和脸部模型,然后自动贴上去,生成新的视频……
研究者通过调研发现,59.6%的受试者认为被这项技术编辑过的视频是真实的视频,反而有20%的受试者认为未经编辑过的视频是假的。
也就是说,经过这个管道的加工生成的视频,足以骗过大多数人的眼睛。
这项技术目前尚未对公众开放,也没有一个普通人可以使用的编辑软件,因为它仍处于研究和测试阶段。研究者来自斯坦福大学、德国马克斯普朗克信息学院、普林斯顿大学和 Adobe 研究院。这份研究已经提交到了计算机图形顶会 SIGGRAPH 2019 上
你可以在下面这个视频里看到,这项技术的编辑效果有多好,编辑出来的视频有多“真实”:
这项技术实际上融合了多种深度学习方法,包括语音识别、唇形搜索、人脸识别和重建,以及语音合成。
简单来说,研究者首先对视频的图像和声音分别进行处理,将需要修改部分的画面和音素分离出来,把修改后语句的音素组装进去,再根据这些单词的发音生成新的人脸模型,最后混合渲染成一个新的视频。
分解步骤大致如下:
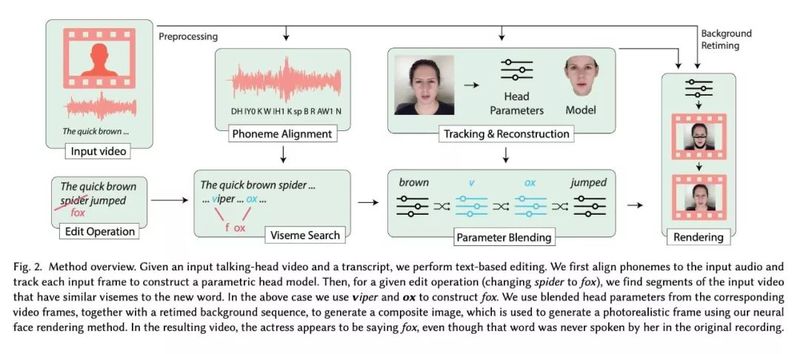
1)输入视频,要求必须是talking-head video,也即以人脸(可以包括上半身)为主要画面,以演讲为主要内容的视频;
2)输入需要修改的字句,以及修改后的文字;
3)使用音素对齐 (phoneme alignment) 技术对视频里的发言进行索引,方便后续工作。音素就是单词的组成部分,比如“苹果”由拼音 ping 和 guo 组成;
4)使用唇形搜索 (viseme search),在原视频里找到需要修改的视频片段和对应的音素;
5.a)听觉上,把修改后词句的音素组装起来,嵌入到原视频里;
5.b)视觉上,对视频当中的人脸进行追踪建模,然后根据修改后词句的发音,为视频的每一帧重建一张下半脸的画面(因为大部分讲话时的面部动作不会涉及鼻子以上),再重新渲染出一段视频(无声);
6)再用视频中演讲者的语音资料合成新的语音,最后混合剪辑成一个新的视频。
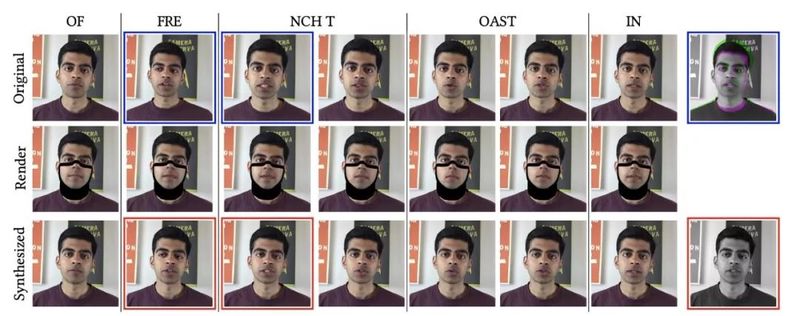
从左到右:不同音素对应的帧;从上到下:原始视频到渲染、最终合成的效果
研究者找来了138名群众参与用户调研,让他们观看三组视频然后给出真或者假,也即未经编辑和编辑过的判断。这三组视频分别为 A(真实),B(真实),C(用 A 作为基础,把 B 的词句替换进去的“假视频”)。而且,研究者事先告诉了受试者,这次调研的主题是“视频编辑”,因此受试者清楚自己看到的肯定会有假视频,因此会更机警地寻找“马脚”。
59.6%的受试者认为 C 组是真实的视频;20%的受试者反而认为原始、未经编辑的视频是假的。
研究者也把这项新技术和 Deepfake、MorphCut 以及 DVP 等“前辈”进行了对比。他们发现,新管道在嘴部动作、口腔内画面合成(牙齿、舌头等)上性能更好,而前辈生成的插入帧往往十分生硬,稍加留意就能看出漏洞。
下图:Deepfake(Face2Face) 在插入帧上出现了牙齿幻影。

下图:DVP 对牙齿的还原出现了高可辨的错误。

下图:DVP 对画中人上肢动作的还原出现了问题,导致了延续性漏洞(影视术语,指剪辑导致了不合逻辑的画面,比如手举着的两帧之间出现了手消失的一帧)。

报错的 Yoshua Bengio
下图:MorphCut(Adobe Premier Pro 里的一个功能,在生硬的编辑中插入计算机生成的帧以使画面顺滑)让画中人面部出现严重的重影

糊掉的 Yoshua Bengio
研究人员发现,输入的视频越长,最终的编辑效果越好,视觉上更自然,对40分钟的视频素材进行训练,便能够达到论文以及视频展示的最优效果;但是,即便只使用极少量的数据,比如两分钟的视频进行训练,最终合成的人脸误差率也才只有0.021,仅比40分钟视频(0.018)高了0.003。
这意味着,这项技术可以用于一段很短的视频,并不需要大量数据也可以达到上乘效果。
论文提到,修改的词句长短和成片质量的好坏并没有直接相关性,但是唇形搜索和音素搜索的结果会影响最终编辑效果。比方说,如果修改词句的口型和发音在数据集里从来没有出现过,效果可能就不会太好。(研究者采用的参数混合方法也可以弥补这一情况,比如 fox 可以用 v 和 ox 组合而成,不一定需要带 f 的词语。)
在用时方面,论文显示 3D 人脸建模每一帧花费110毫秒,也一段长度1小时、60fps演讲者一直在讲话的视频(下同)需要396分钟或者六个半小时;音素对齐需要大约20分钟;唇形搜索最短仅需10分钟,最长2小时;人脸合成每帧需要132毫秒,1小时视频需要将近8小时合成,过程中的神经网络训练用时最长,需要42小时左右。
完成了上述步骤后,编辑者就可以对视频随意修改,如果只是修改部分词句的话,花费的时间和训练/前期准备相比可忽略不计。
比方说某政客演讲完,理论上最快两天后网上就能出现一段意思被完全扭转,但完全看不出任何问题的“假视频”。
而如果放到新闻的语境当中,这项技术突然变成了最令人们担忧的事情。这一方法对计算量有一定需求,因此路人不一定有能力完成,但如果是黑客或者敌对政治人物想要对受害者进行有组织的污蔑攻击,本篇论文所描述的这一方法简直不能更好用。
今天,英国一家营销机构在其 Instagram 账号上发布了一小段扎克伯格的讲话。在视频中,扎克伯格戴着标志性毫无“人味”的表情,表示“想象一下,有一个人,完全控制着数十亿人被盗的数据,他们所有的秘密,他们的生活,他们的未来。我完全归功于幽灵。幽灵告诉我,谁能掌控数据,谁就能掌控未来。“
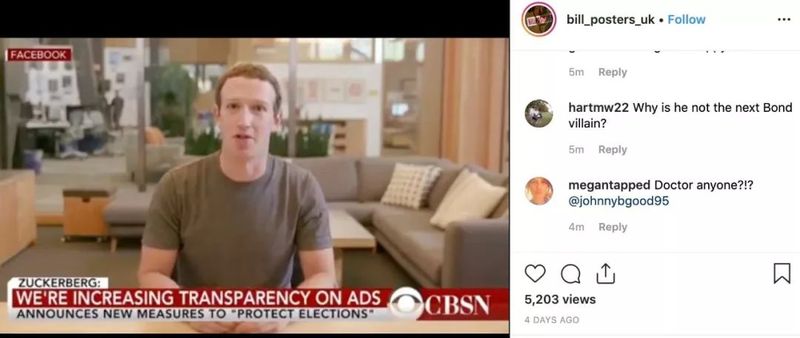
”幽灵“是这家营销机构正在推广的一个装置艺术展览,这则视频其实这场展览的营销。视频本身也是用 Deepfake 或者类似的技术制作的,技术来自于以色列公司 Canny.ai,声音则是找了一个跟扎克伯格完全不像的人努力装出来的。事实上,这家营销机构还”找来了“特朗普、金·卡戴珊、摩根·弗里曼等著名人物,制作了类似的视频。
如果说这些视频人畜无害的话,那么另外一则技术含量根本没多高的剪辑视频,则对一位美国顶级政客带来了巨大的伤害。
前几周,两段美国众议院议长南希·佩洛西“口齿不清”的视频流传于网上。很快,这段视频就被人发现使用了非常无聊的剪辑手法,让佩洛西看起来像是喝多了或者快要中风一样。包括 Facebook 在内的一些社交网站和视频平台拒绝取缔这些视频。
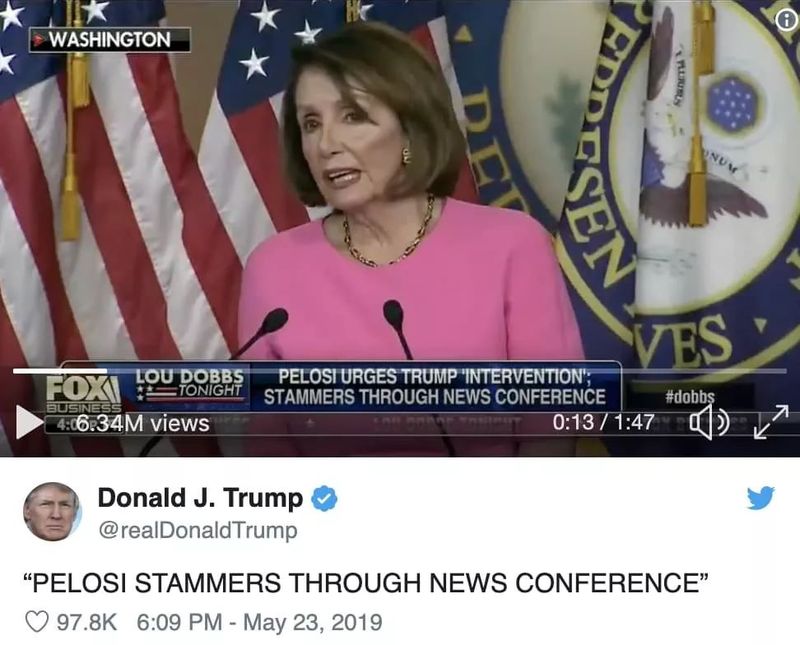
在当前社会极端化和对抗日益严重,以及假新闻盛行的大环境下,类似的视频往往具有极强的传播势能。而更先进的技术让视频的质量变得更好,相应地对受害者的伤害,以及对社会造成的进一步撕裂,只会更加严重。
研究者在论文中指出,他们认为这项研究的主要目的是简化视频编辑人员(以及内容产业整体)的工作压力。比如那些念错台词或者漏拍的场景,现在可以直接用深度学习算法生成精确的画面和声音,不再需要重新花大价钱重拍。
另一个重要的使用场景是翻译。论文中(以及配套的视频里)演示了跨语言生成视频的效果,因为本质上被剪辑的不是词语,而是口型和音素,不受语言的限制(比如,许多欧洲国家语言共享音素)。
如果有一部电影需要译制成西班牙语版,过去的做法是译制厂直接后期配音。而现在有了这项技术,可以直接生成发音准确,而且口型同样准确的译制片了。
当然,电影只是一个极端的案例。不那么极端的话,比方说你是一个美妆博主,想要把观众群扩展到海外,正好可以用这项技术生成其他语言版本的视频,即便发音不百分之百精确也没有关系。
最后一个使用场景,是生成二次元偶像带视觉形象的虚拟语音助理。有了这个技术,应该就可以生成可以看见的林志玲/郭德纲导航了。研究者在论文中提到,除了用神经网络,他们的技术也可以搭配 macOS 的语音合成器 (speech synthesizer) 使用,让合成语音更加容易。


